“Urban Data” & “Civic Data Trusts” in the Smart City

On June 24, Sidewalk Labs, a sister company to Google, released its three-volume, 1,500-page Master Innovation and Development Plan (MIDP) containing its draft proposals for a smart-city project in Toronto. This post focuses Sidewalk Labs’ discussion of “Creating a Trusted Process for Responsible Data Use” (Part 3 of a chapter on “Digital Innovation” -- Volume 2, Chapter 5--) (Volume 2, Chapter 5. Part 3 proposes the use of a “civic data trust” to govern the “urban data” generated within the proposed smart city project area.
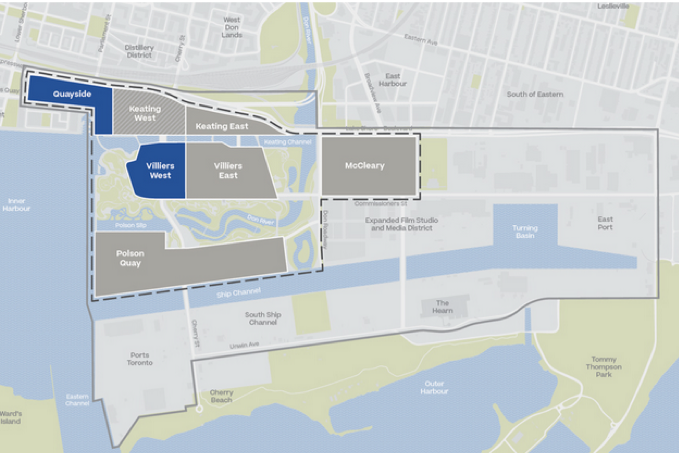
I will also be examining Sidewalk Labs’ 41-page “Digital Governance Proposals for DSAP Consultation” released in October 2018. The latter document provides more detailed information on urban data and how data collection may occur in publicly accessible spaces. As this map created by Sidewalk Labs illustrates, the original proposal was for the Quayside neighbourhood, but Sidewalk Labs expanded its proposal to the area outlined in checked line that it terms the “IDEA District.”
Sidewalk Labs proposes two concepts: “urban data” and “data trusts.” First, I explain the concept of urban data and its associated challenges, and secondly, I examine Sidewalk Labs’ proposed system of visual symbols to alert people of data collection in public spaces. Third, I explore Sidewalk Labs’ proposal to make publicly accessible data a default within the project area, and then turn to consider the concept of data trusts before providing a brief conclusion.
What is “urban data?”
According to Sidewalk Labs’ MIDP, urban data is data collected in the “city’s physical environment, including the public realm, publicly accessible spaces, and even some private buildings.” Urban data, as defined by Sidewalk Labs, consists of three subcategories:
• Type 1) data collected from public spaces like streets and parks.
• Type 2) Data from publicly accessible private spaces like stores and building lobbies or courtyards.
• Type 3) Data from private spaces not controlled by those who occupy them, such as office thermostats.
“Urban” versus “Transaction Data”
A principal feature of urban data, in Sidewalk Labs’ terms, is that it is “anchored to geography, unlike data collected throughwebsites and mobile phones.” Sidewalk Labs terms the latter “transaction data” as it is information that “individuals affirmatively — albeit with varying levels of understanding — provide information about themselves through websites, mobile phones, or paper documents.” Simply put, Sidewalk Labs argues that data collected in physical spaces is fundamentally different from that gathered through mobile devices.
A defining feature of urban data is the difficulty of obtaining informed consent. Sidewalk Labs acknowledges individual consent is “hard to achieve in public or publicly accessible spaces.” Sidewalk Labs sees no informed-consent requirements if the data collected is not personal information. Canadian law requires consent for the collection of personal information that relates to an identifiable individual.
Transaction data involves user consent and is based upon contractual terms-of-use agreements between users and typically for-profit entities. People grant consent for parties to collect, store, and use their data when they download apps or sign up for services. However, a growing body of research shows that people generally do not read or fully understand the often-long and complex contractual agreements. Just because people have clicked the ubiquitous “I agree” does not mean that they appreciate the terms or comprehend how their data may be used.
In contrast to the consent-based nature of transaction data, Sidewalk Labs argues that “individual consent is hard to achieve in public or publicly accessible spaces.” People don’t sign consent forms or receive pop-up notifications on their phones when they enter environments where they may be under surveillance from CCTV cameras or when sensors measure numbers of bicyclists at intersections. Sidewalk Labs’ use of “urban data,” the company argues, reflects the “practical challenges in obtaining meaningful consent” for data collection in the urban environment.
Problems with “Urban Data”
It’s highly problematic that the vendor proposing a smart-city development is defining terms and proposing data governance strategies that would govern the vendor’s business as this gives the appearance of the trust’s lack of independence. In its MIDP, Sidewalk Labs says that it heard public concerns about data collection in “the city’s public realm,publicly accessible spaces, and evensome private spaces — whether or not that data identifies specific individuals.” The company’s response, however, was not to propose restricting the type of data collected or strengthening privacy legislation. Instead, Sidewalk Labs’ created “a new category of data called ‘urban data’.” The company argues that urban data “seems worthy of additional protections” as this type of data may contain personal information, along with non-identifiable information, and since individual consent can be difficult to obtain in relation to public spaces and publicly accessible private spaces.
There are several problems with Sidewalk Labs’ use of the term “urban data.” First, and most importantly, urban data is unrecognized in Canadian law. In proposing a new term--and one unrecognized in Canadian law--Sidewalk Labs can strategically append certain characteristics, thereby defining the concept in a way that serves its interests. Under Canadian law, the relevant distinction is not between data gathered in physical spaces and mobile applications (i.e., Sidewalk Labs’ distinction between urban and transaction data), but between personal information related to an identifiable individual and non-identifiable information (see Canada’s Personal Information Protection and Electronic Documents Act). Using CCTV cameras to record license plate numbers in a parking lot constitutes personal information related to an identifiable individual, while using sensors to detect the presence of pedestrians or bicyclists at intersections does not.
Problems of Consent
Urban data may usefully describe a type of data collected within the built environment, but creating a new term that brings together personal information and non-identifiable information does not strengthen data protection. The public consultation regarding the Quayside project identified concerns about privacy and the collection and use of data from public or publicly accessible spaces, as Sidewalk Labs notes in its master plan. But, instead of addressing those concerns directly, Sidewalk Labs’ response was to focus on the issue of individual consent.
Sidewalk Labs argues that there are differences in individual consent for its three subcategories of urban data. Individuals in Type 1 (public spaces like parks) and Type 2 (publicly accessible private spaces like stores) have “little control over the collection of urban data.” This is because the collection of non-identifiable data in public spaces or publicly accessible private spaces does not require a person’s consent. However, even when personal information is collected, such as through cameras, Sidewalk Labs’ solution is not to restrict the collection of identifiable data. Instead, Sidewalk Labs emphasizes de-identifying data, which is itself a problematic practice that I discuss below. For Type 3, data collected from private spaces, there is an acknowledgement that there may be issues of privacy and consent that preclude data collection or making that data publicly accessible.
Consent through Signage
On April 19, 2019, Sidewalk Labs announced prototype signage that it developed in collaboration with industry and civil-society groups that endeavours to provide an “easy-to-understand language that clearly explains data and privacy implications of digital technologies.” In Sidewalk Labs’ perspective, the proposed symbols would address public concerns about data collection in public spaces--even of non-identifiable data--by proposing to obtain individual consent through signage in the physical environment. Despite the importance of the symbols to Sidewalk Labs’ data collection practices, it oddly makes only a cursory reference to its signage prototypes in its master plan and provides no examples of its designs.

The design incorporates a series of hexagons: one to indicate the technology’s purpose, another to identify the entity responsible for the technology, the third containing a QR code that allows interested individuals to learn more, and the final hexagon to provide information on privacy. The privacy hexagon uses one icon to indicate the technology type (video, image, audio, or otherwise), and another icon indicating identifiable information. For example, yellow indicates identifiable information, blue for de-identified before first use, and an absence of this hexagon indicates the information is non-identifiable.

As the above image shows, the four hexagons are supposed to indicate collectively the data collection type (planning), the entity responsible (Sidewalk Labs), the QR code for more information, and the degree of identifiable information (image de-identified). Depending on the size and location of the signage in public spaces, individuals may have to get quite close to the signage and/or the public space under surveillance before learning the type of data collection being conducted in that space, especially if they want to scan the QR code.
Problems with Signage-based Consent
Sidewalk Labs’ proposed signage is not sufficient to ensure meaningful informed consent. Using signs to inform people of data collection in public places is certainly preferable to not informing people. However, placing the signage in public spaces doesn’t guarantee that people passing through the space will observe or even understand the symbols. Unlike commonly used symbols for hospitals or toilets, the general public probably has little awareness of the prototype signage, and it’s a long process for symbols to become universal standards. While recognizing that Sidewalk Labs worked with industry and civil-society groups to develop the most comprehensive yet simple visual language relating to data collection, the signs pose certain challenges. It’s unclear how visually impaired people may be able to interpret the signs or if the information will be available in multiple languages. As the signage incorporates QR codes, only people with smartphones are able to learn more about the data collection, which leaves certain populations like seniors or low-income people with little ability to learn more.
No Way to Opt Out
Signage-related consent relies upon indirect consent in contrast to transaction data where there is typically a direct consent, such as clicking “I agree.” Even when users have the option of either clicking “I accept” or “I do not accept,” the assumption is that individuals are providing informed consent to the agreement. However, people tend not to read corporate policies and may not understand the nature or extent of the data collection. Further, companies have considerable latitude in crafting their policies and reserve the right to change the terms of their agreements without notice to the user.
People may decide not to use a certain app or service, or chose an equivalent service that offers different data collection practices. However, when data collection is tied to locations or infrastructure like transit, there is no way to opt out of data collection short of leaving the area in question. People who decline to have their data captured may consider certain parts of the city--and certain services--off limits. A related problem is the blanket nature of consent. If sensors collect different information in the same area, people are not able to grant consent for one purpose and decline consent for another.
Publicly Accessible Data by Default
During the consultation period, critics raised concerns about individual privacy and fears that certain data collection practices can harm specific groups, especially marginalized communities. Critics also raised concerns that Sidewalk Labs--or its sister company Google--would control and own the data generated in the proposed smart city. Sidewalk Labs says it responded to the first concern by creating the term “urban data,” and proposing signage to alleviate concerns about data collection in publicly accessible space.
Sidewalk Labs responded the second concernin its Digital Governance Proposals document and Master Innovation and Development Plan.“Data collected in the public realm or in publicly owned spaces should not solely benefit the private or public sector,” Sidewalk Labs contends, “instead, it should benefit multiple stakeholders, provided any privacy risks have been properly minimized.” Sidewalk Labs argues that unlike transaction data, which is proprietary to the data-collecting entity, most urban data can “reasonably be considered a public asset” or “a community or collective asset.” Whether one uses the term public, community, or collective asset, the emphasis for Sidewalk Labs is on the publicly accessible nature of the data, such as traffic patterns or pedestrians crossing intersections. Urban data, Sidewalk Labs argues, should be “publicly accessible by default (if properly de-identified).”
As Type 1 and 2 data are collected in public spaces, Sidewalk Labs considers that data to be “public assets” that should be made “publicly and freely available” to those who wish to use the data. (Note: data that contains personal information must be reviewed by the civic data trust, discussed below, and deidentified before being made publicly accessible). In contrast, data from Type 3 places, such as security-camera footage from private residences is not “reasonably considered a public asset.” Collection of this type of data requires consent because the spaces are private, but data collection is not off limits.
Problems with Making Data Publicly Accessibly by Default
It’s highly problematic that Sidewalk Labs responded to public concerns about privacy and data collection in public spaces with the declaration that most urban data should be publicly accessible by default. This proposal conflates the two complaints: 1) concerns of privacy and data collection in public spaces, especially by companies, and 2) concerns about dominant actors, especially companies, controlling that data. These two issues are not the same.
On the surface, Sidewalk Labs’ proposal for publicly accessible data as a default responds to public concerns about a dominant, especially corporate, actor controlling data relating to smart city project. By ensuring no one actor can dominate data collection practices, the argument goes, there will be opportunities for all. However, this emphasis on publicly available data as a default also serves to normalize corporate practices of pervasive data collection and accumulation. Two issues stand in the way of making publicly accessible data the default practice: 1) individual consent and 2) privacy. To tackle the first challenge, Sidewalk Labs introduced signage, a problematic practice discussed above. To address, in part, privacy concerns, the company proposes deidentifying data (under certain conditions) before it can be made publicly available.
With its prototype signage and emphasis on de-identification, Sidewalk Labs is proposing practices that sees all urban data as potentially collectable, even within private spaces. As scholars Ellen Goodman and Julia Powles have noted, in Sidewalk Labs’ formulation there are “no limits on data collection or use,” nor “will there be surveillance-free zones.” It is unclear how Sidewalk Labs reconciles its emphasis on pervasive collection of urban data with its promotion of privacy by design, which embeds privacy protections into the design and operation of the technology.
Alongside pervasive data collection, Sidewalk Labs’ proposals rely upon urban data deidentification. For data to be made publicly accessible, it must be nonidentifiable data (that is not pertaining to an identifiable individual) or data that is deidentified through technical means. Sidewalk Labs admits the deidentification of data “may not completely eliminate the risk of the re-identification of a data set” but argues that when data is deidentified corrected, “the process can produce data sets for which the risk of re-identification is very small.” Depending on the techniques used, under certain circumstances it is possible to re-identify some datasets.
Entrenching Market Advantage
Making data publicly accessible by default will likely not address concerns about Sidewalk Labs’ capacity to play a dominant role in practices relating the amassing and interpreting data. Simply because data is publicly accessible does not mean that all actors can equally access, store, or process the data to deliver products and services. Companies with significant stores of proprietary data, algorithmic modeling capacity, and commercial distribution infrastructure have market advantage. In other words, Sidewalk Labs doesn’t need proprietary data access to monetize the project. SidewalkLabs need not have proprietary data access as it can capitalize upon Google’sdominant position in data collection and analytics.
Civic Data Trust
Alongside the creation of “urban data,” the second important issue is Sidewalk Labs’ proposal of a data trust, which is another concept it can define in its own interests. Data experts and scholars are increasingly considering data trusts as a possible mode of governance, including in relation to smart cities. Data trusts can involve different arrangements of actors, whether private or public organizations, or a combination of the two with the data being accessed in either direction.
As discussed by the Open Data Institute, a U.K. non-profit, such trusts are often associated with the idea of public oversight of data with data stewards responsible for determining who has access to data, under what conditions and who can benefit. There are potential benefits of data trusts. Independent trusts, for example, may help stakeholders balanceconflictingviews about how data should be shared and with whom. As well, data trusts could make control more representative over how data is used and shared, especially if it gives voice to peoplewhomight not otherwise have input about ifor how their data is collected or used.
After facing considerable criticism for not publicly addressing issues of privacy and data governance, Sidewalk Labs released its first proposed framework for data governance in October 2018 in its “Digital Governance Proposals for DSAP Consultation.” In that document, the company proposed a civic data trust, an “independent entity to control, manage, and make publicly accessible all data that could reasonably be considered a public asset.” In its master plan, Sidewalk Labs proposes that this independent entity would also oversee “the approval and management of data collection devices placed in the public realm, as well as addressing the challenges and opportunities arising from data use, particularly those involving algorithmic decision-making.”
From Data Trust to “Legal Structure”
As originally proposed by Sidewalk Labs, the civic data trust appeared to be a legal entity. However, Sidewalk Labs again faced criticism, this time for the vagueness of its conception of trusts and questions of how the trust would operate under Canadian law. Trusts under Canadian law are ways to manage assets that are owned for the benefit of specific, identifiable beneficiaries. But Sidewalk Labs failed to specify who it considers to be likely specific beneficiaries for the trust. Would possible beneficiaries be residents in smart city area or Toronto residents in general? Complicating this the question of beneficiaries, as under Canadian law, the general public cannot be a beneficiary of a trust.
In response to this criticism of its data governance proposal, in its master plan, Sidewalk Labs departs from its original conception of a civic data trust and instead proposes an “independent urban data trust.” Despite the similar name, Sidewalk Labs argues that it is not “a ‘trust’ in the legal sense.” Instead this trust is a “legal structure that provides for independent stewardship of data,” a definition of a data trust from the Open Data Institute. How this trust would operate, its structure and regulatory powers, the source and scope of its legal authority, and its relation to other regulatory bodies and governmental departments within the city of Toronto and province remain unclear.
Proposal of Public Agency
In its master plan, Sidewalk Labs proposes that the trust develop in two phases. In the first phase, the emphasis would be “on getting the entity up and running quickly to establish the rules and give it experience working through use cases.” What cases? Sidewalk Labs suggests that its own data collection projects in Quayside would be ideal test cases. In this phase, the trust would operate through contracts: each entity that wanted to collect or use data would enter into contract with the trust and any breaches “would be legally enforceable, with breaches actionable in court by the Urban Data Trust entity.”
In the second phrase, Sidewalk Labs envisions that the trust would be transformed into a public-sector agency or a quasi-public agency in order to apply the rules “to a wider group of organizations and places.” Again, how this trust would operate as a public/quasi-public agency, its relation to other public bodies in Toronto or Ontario, and possible funding are unclear, as it the political and public appetite for creating a new public agency.
Problem of Vendor Proposing Data Governance Rules
It is highly problematic for the entity that would be regulated by the trust (i.e., the ‘regulatee’) to propose the structure, operation, and regulatory power of the regulator. Certainly, it’s self-serving for Sidewalk Labs to submit that its projects should be first in line for consideration by a neophyte regulator that it proposed. If the data trust goes ahead, this first phase--and Sidewalk Labs’ involvement with the trust--would likely shape discussions of how (or even if) the temporary trust should involve into something more permanent.
It’s important to note that Waterfront Toronto stipulated in its Request for Proposal (RFP) that the vendor would work closely with Waterfront Toronto to “create the required governance constructs to stimulate the growth of an urban innovation cluster, including legal frameworks (e.g. Intellectual Property, privacy, data sharing).” In other words, Waterfront Toronto required the successful “partner” to co-create governance frameworks that would govern not only the successful vendor’s operations but also an important area (Quayside) along Toronto’s valuable waterfront. Waterfront Toronto’s delegation of governance authority to a private-sector vendor is troubling, but equally problematic is the creation of Sidewalk Toronto, the quasi-legal organization composed of Waterfront Toronto and Sidewalk Labs to develop plans for the proposed smart city.
The Plan Development Agreement, signed by Waterfront Toronto and Sidewalk Labs in July 2018 to govern the creation of the MIDP stipulates a very close working relationship between the two organizations. Despite this, according to Waterfront Toronto, at some unspecified period, the “roles of the two organizations then separated, with Waterfront Toronto focused on creating a robust framework for review and evaluation” of Sidewalk Labs’ master plan. For my purpose, the key point is that Waterfront Toronto appears to be tryingperform an impossible task: operate as a supposed arms-length public corporation tendering bids and evaluating vendor’s submissions and, at the same time, forming a close collaboration with the vendor. At the very least, Waterfront Toronto does not appear to be acting as the public corporation charged with representing the public interest.
Another challenge in relation to the proposed data trust are the trustee’s roles in creating and enforcing rules regarding data collection, storage, protection, and use, including commercialization. Depending on how the regulatory body is structured and its legal authority, the data trustees, whether public or private actors, could have considerable regulatory power. Sidewalk Labs provides few details on how the trust’s roles beyond granting approval for and overseeing data collection, access, and use. However, it appears to be proposing that the trust should have the authority to audit and investigate data collection and use. This would give data trustees significant power, similar to that of a government regulator, so how a data trust is structured and who operates it are importantquestions.
Selling and Monetizing Data
After facing public opposition, Sidewalk Labs asserts “that it would not sell personal information to third parties or use it for advertising purpose.” The company also “commits to not share personal information with third parties, including other Alphabet companies, without explicit consent.” As long as consent is obtained, however, Sidewalk Labs can freely sell, share, or use personal information for advertising, as long as it complies with rules established by the data trust. As to what constitutes “explicit consent”, Sidewalk Labs proposes using “physical signs notifying people of a data device or informational websites describing a service or program in greater detail.” It’s difficult to see how relying upon people to notice and understand signage in public spaces constitutes “explicit consent” in any meaningful way (although, of course, the data trust that Sidewalk Labs would like to see established could simply define signage to equal explicit consent.)
It is also unclear what restrictions or limitations might the data trust impose on the selling of data containing personal information. According to Sidewalk Labs, the data trust would not prohibit the sale of personal data or its use in advertising, but “a higher level of scrutiny should be placed on projects that want to use personal information for these purposes.”
It also remains to be determined what processes might the data trust follow to approve requests for data collection and use. In its October 2018 data governance proposal, Sidewalk Labs emphasized that “many applications” to the trust, generally for non-identifiable data” will be able to be “self-certified” by the entity applying to the data trust. For these self-certified applications, Sidewalk Labs sees the role of the data trust to “reliably and speedily—potentially, automatically—approv[e] accurate, self-certified applications.” While trust applicants will likely prioritize a speedy, especially automatic, approval to applications, people concerned about privacy and about data collection in public spaces would place greater value on a thorough, independent review of data collection practices.
Conclusion: Shaping the Rules of Engagement
In several respects Sidewalk Labs provided us with greater detail on how it conceptualizes urban data and the roles of the data trust in its October 2018 data governance plans than in its 1,500-page Master Innovation and Development Plan. In its 2018 document, Sidewalk Labs proposed that data be publicly accessible by default and that signage constitute consent in public and publicly accessible spaces. It offers a new category of data--urban data--that is unrecognized in Canadian law. It also proposed an ill-defined data trust that may evolve into a public/quasi-public agency. These proposals, however, are not set in stone. How Sidewalk Labs’ master plan may evolve following public consultation, review by Waterfront Toronto, evaluation by the three levels of government, and its own changing sense of its self-interest is unknown.
Waterfront Toronto’s ceding of regulatory authority to Sidewalk Labs for the co-creation of rules on intellectual property, data, and privacy put Sidewalk Labs in the driver’s seat to shape rules in its favour. In its conception of the smart city, there are no surveillance-free zones, even in privately owned spaces, as long as occupants consent to data collection. For Sidewalk Labs, a new class of data--urban data--should be publicly accessible by default with exceptions for data with personal information or for proprietary datasets. Personal data could be sold and used in advertising if people grant (undefined) “explicit consent.” Sidewalk Labs underlined its public commitment in its master plan “not to sell personal information to third parties or use it for advertising purposes,” and commits not to sharing such information “with third parties, including other Alphabet companies, without explicit consent.” With consent, then, it would appear that Sidewalk Labs will be involved in the sharing of personal data with other parties, which could include Google. Sidewalk Labs clearly stands to benefit from these rules that facilitate the mass accumulation and processing of data.
There are a number of serious questions that should be answered before any decisions are made about the project moving forward. Instead of proposing structures to govern data, we need to ask if certain types of data should even be collected in the first place. Is there any type of data that we consider “off limits” for government or companies to collect? For example, some scholars and activists arguing that facial-recognition data should not be collected by either governments or companies. Informed consent is another challenge in regards to data collection in public spaces. What does “informed consent” look like in a smart city in regards to data collection and use? Sidewalk Labs worked collaboratively with industry and civil-society to design its design signage, which is the visual equivalent of companies’ terms-and-service agreements. But what does opting out of data collection in a smart city look like? If someone declines to give consent for the collection of data in public spaces, what are their options short of leaving the area? Only after we’ve debated what data collection is acceptable or socially desirable should we move onto discussing how data should be governed and by whom.
Following the release of Sidewalk Labs’ enormously complex and lengthy Master Innovation and Development Plan, questions of governance are critical. Instead of debating the potential benefits and drawbacks of “urban data” and an “urban data trust,” we need to think more broadly about what kind of city we want in Toronto and how technology should serve society. Instead of letting the vendor shape the debate over data, privacy, and consent in public spaces, we have to have a meaningful public discussion about these issues. We also need to bring all levels of government back into the picture to perform the critical, necessary role of representing the public interest.
This post is based on a presentation I gave on July 2, 2019 to the Data Governance: Between Concepts and Case Studies Workshop at the Humboldt Institut für Internet und Gesellschaft (HIIG) in Berlin.
